Session 1 (09/10/2025)
Summary
You will learn about the various types of variables such as built-in primitive types, structures, and classes. Also covered are pointers and references to variables and the semantics of passing and retrieving data from functions as well as conversions between various types.
Declarations & definitions
You already know that clean coding in C++ separates declarations from definitions:
- Declarations are (usually) written in header files (
.h,.hpp,.hxx,.Hare the most common extensions you'll come across) - Definitions are (usually) written in source files (
.cpp,.cxx.,.C)
Including the declarations from a header file in a source file is done using
the #include preprocessor directive; like this:
#include <vector>for standard library headers and headers in standard system locations like/usr/include.#include "mystuff.h"for user-defined headers.
Be careful that, according to this scheme, definitions should never be placed in the header files, where they can be included multiple times within the same program or translation unit! This could violate the One Definition Rule (ODP), which states that only a single definition can exist for classes and non-inline functions within your entire program, or for templates and types within a single translation unit. (learn more here)
If you want to know more about source & header file organization I suggest reading through chapter 15 (Source Files and Programs) in Stroustrup's C++ book.
Headers: C vs C++
More often than not you'll come across legacy C header files being used in C++, such as math functions from the math.h
header file or standard I/O functions from stdio.h.
You might encounter these headers either as #include
<math.h> or #include <cmath>. Both statements include the same file, but
the latter wraps the contents of the header in the std namespace for
consistency with other C++ standard library features. The direct consequence of
this is:
- If you include
math.h, you can use its functions likedouble sin(double x)directly. - If you use
cmath, you must remember they live in thestdnamespace;double std::sin(double x).
When using C++, you should therefore always use the header with the c prefix instead of the .h suffix.
For other legacy C headers, there often exist better C++ alternatives, such as chrono instead of ctime or the
utilities provided by random instead of the rand function from cstdlib.
Types
Primitive data types
These data types are built in right into the language and are available out-of-the-box without any prior definitions or declarations.
- Boolean:
bool(values are the literalstrueorfalse) - Integer:
int(unsigned,long,short),size_t(used for sizes of things like arrays, guaranteed to be "large enough", the type of anysizeofexpression, see here) - Floating point:
float,double,long double - Character:
char(you might encountersignedandunsignedvariants used as numbers) - For the sake of completeness:
voidandenumare also primitive types
Aggregate data types
The above primitive types are often insufficient to represent your data logically. Aggregate types give you the possibility to keep related data items together. Examples are structures, classes, arrays, strings, etc.
Structures
A struct is an aggregate of elements of arbitrary types. It's a user-defined
type that holds the data you want it to hold; for example:
struct Restaurant {
std::string name;
bool served_delicious_food_today;
}; // Don't forget the semicolon!
// Defines a variable resto of the type Restaurant:
Restaurant resto;
// Members can be accessed using the 'dot' notation:
resto.name = "Atrium";
resto.served_delicious_food_today = false;
Historically, C++ structures could be considered "C heritage". Sometimes you'll come across the name "POD" or "Plain Old Data" structures (see here) which are "passive" collections of data without any Object Oriented features or associated operations. (Although strictly speaking, C++ allows you to derive from structures and define member functions on them)
I advise you to use struct for very simple things only! The reason for this
is data hiding; read on about classes, and you'll see what that means.
Classes
Technically speaking, a class is pretty similar to a struct in C++. It's an
aggregate of elements of arbitrary types, with the associated operations
for the class and instances (objects) of that class. By creating a new
class, you effectively create a new user-defined type. You can think of a class
as a recipe for making cookies: it specifies how a cookie should be
made, it does not create one yet.
The definition of a class contains all the necessary information to create an instance of that class:
- data members (often called fields): the data contained in the type
- member functions (often called methods): the procedures to work with the data (or with the class)
An object is an instance of a class. Just as you can make physically real, existing and delicious cookies following a recipe; you can make real, memory-occupying, and data-containing objects of a class.
Once again: classes are recipes, objects are cookies!
A small example of defining classes follows. This is a class definition
(Cookie.h):
#ifndef COOKIE_H
#define COOKIE_H
class Cookie {
public:
// A standard cookie has 4 bites; no more, no less. This constructor
// deals with the creation of a new cookie.
Cookie();
// Take one bite from the cookie. Only 4 bites / cookie are allowed.
void take_a_bite();
private:
unsigned int m_bites; // Number of available bites left
}; // Do NOT forget the semicolon!
#endif /* COOKIE_H */
... and the definition of its members (Cookie.cpp)
#include "Cookie.h"
#include <iostream>
// A standard cookie has 4 bites; no more, no less. This constructor
// deals with the creation of a new cookie.
Cookie::Cookie() : m_bites(4) {
// Nothing else here
}
// Take one bite from the cookie. Only 4 bites / cookie are allowed.
void Cookie::take_a_bite() {
if (m_bites > 0) {
m_bites--;
std::cout << "Taking a bite, " << m_bites << " bites left." << std::endl;
} else {
std::cout << "No more bites, you finished the cookie!" << std::endl;
}
}
... and creating & using objects of classes:
#include "Cookie.h"
...
Cookie a; // Bake a cookie
Cookie b; // Bake another one
// Eat the first one
for (int i = 0; i < 5; ++i) {
a.take_a_bite();
}
// Take a bite of the other one
b.take_a_bite();
Note the explicit specification of the visibility of Cookie's members:
The constructor and the bite-taking method are public while the number of
bites is a variable being kept private. The former means that all code
outside the Cookie class may call these methods. The latter means that no
code outside the Cookie class may access (neither read, write, nor call in the
case of member functions) the private variable.
The purpose of the distinction between public and private entities is to
hide as much data, functionality, and implementation details from
"outside-world" entities that don't need to see it and to provide a clear and
logical API
for the class. This is a very important concept in writing modular code!
The convention is, therefore, also to list your public members first in the interface of your class, such that users of
your class have a clear overview of the members they are allowed to interact with.
Structures vs classes
The only difference between classes and structs is that classes have
private visibility for all their members by default while structs
have public access. Apart from this "default-visibility" difference (which
doesn't really matter most of the time, since you're encouraged to specify the
visibility explicitly like in the above example), there are no other
differences in behavior between a struct and a class. g++ even generates
exactly the same code for both. Check the generated assembly code if you
want to know for sure. (gcc allows you to look at the generated assembler
code with the -S flag. You can "demangle" C++ names with c++filt if you
like. Learn more here about name mangling in C++.)
Despite these similarities, it's highly customary to use structures for the simplest things only and stick to classes for all other serious uses.
Standard library types
Important
The C++ standard library provides plenty of classes for you to use. Instead of
defining your own vectors, strings, streams, linked lists, and other containers,
you are way better off using the std types as much as you possibly can. Don't
reinvent the wheel: always check if "that thing that you need" is available in
the standard library!
Just to get you started, have a look at the following features of std (click
on the names, they link to documentation):
- Strings and streams:
string,fstream,stringstream - Containers (STL):
vector,list,array,map,stack,queue,deque,set - Algorithms: sorting, comparison, searching. Also here.
Familiarize yourself with the above features of std to know when and
how to use them!
Choices, choices everywhere!
Some of the most used containers are listed above. Which one should you use for your problem?
As you know, choosing the right data structure or container for the problem at hand has a great influence on the flexibility and speed of your code. Make sure you know the characteristics of the containers you use.
This handy decision chart might get you on the right track in case of doubts.
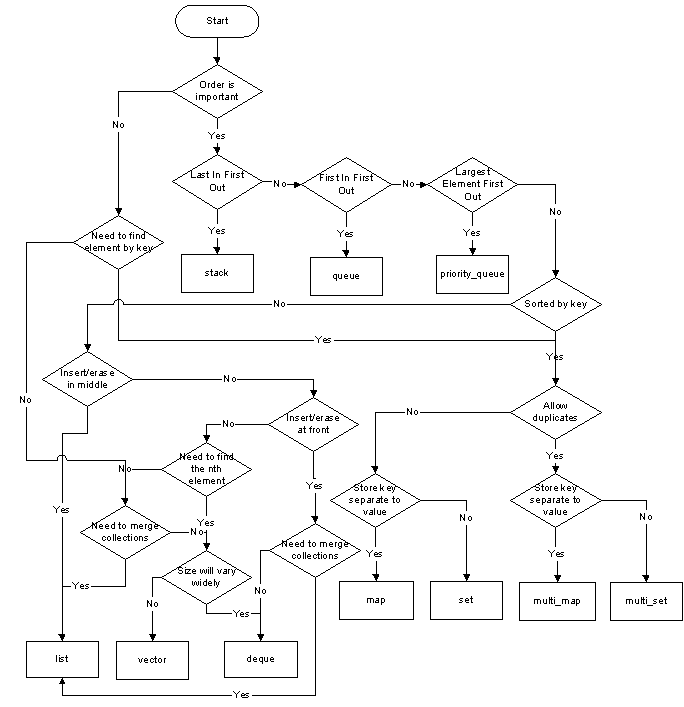
Additional containers
C++11 included some interesting additions to the Standard Template Library of containers. You might find the following two containers useful at some point.
std::tuple
You are probably familiar with the std::pair container:
std::pair<std::string, int> ingredient;
ingredient.first = "Tomatoes";
ingredient.second = 3;
As the name suggests, a pair is limited to containing two objects.
The addition of variadic templates to C++11 allows to extend the notion of a
pair that contains two elements of heterogenous types to a tuple that can do the same with an arbitrary number of
elements (#include <tuple> to make it work).
std::tuple<std::string, int, bool> ingredient;
ingredient = std::make_tuple("Tomatoes", 3, true);
Note the use of std::make_tuple, See here for more
details.
The values from a tuple can be "unpacked" with (honestly, a slightly cumbersome) std::get:
std::string name_of_ingredient = std::get<0>(ingredient);
int amount = std::get<1>(ingredient);
bool optional = std::get<2>(ingredient);
A useful application of std::tuple is to return more than one value from a function.
std::unordered_map
Read both documentation pages:
What is the difference between the two, both semantically and in terms of time complexity?
Pointers
Instead of repeating what you already know about pointers in C / C++ or running the risk of a confusing explanation, I suggest that you read the following:
- The quite extensive & general Wikipedia article on pointers, or at least the section on C and C++
- More in-depth explanation with examples on the cplusplus website
An additional point worth noting is that the C++11 standard defines a null pointer
constant, nullptr, to explicitly denote the null pointer. I.e., instead of
double* foo = 0;
write
double* foo = nullptr;
The use of nullptr is highly encouraged over the use of the integer 0 or
NULL (legacy C) since it's more type-safe when overloading functions. Do some research and try to
create a short example to show that the wrong function can be called when 0
is used to denote a null pointer instead of nullptr.
*When using an outdated compiler: in order to use nullptr, you should probably tell your compiler
you're using C++11 features by adding
the -std=c++11 flag to the compilation flags.
Similarly, if you want to explicitly enable C++14
or C++17, you should use the -std=c++14 and -std=c++17 flag respectively.
Have a look around the Object Tracer code and its
accompanying CMake files to learn how to add -std=c++17 to your CMake files properly.
If you want to check which type of compiler supports which feature, check the compiler support page on cppreference.com.
Segmentation faults
Since all sorts of invalid handling of pointers is a typical cause of crashing programs and the number one reason you'll see segmentation faults, now is a good time to read more about it.
References
References are conceptually pretty similar to pointers. Defining a reference to a variable effectively creates a new name to access the variable (just like a pointer could be seen as a different way to access an existing variable). Read this article for a more thorough explanation with examples; for a specific comparison to pointers, you should certainly read the "Relationship to pointers" part. A slightly more technical explanation can be found on this website which also covers C++11 rvalue references: We'll cover these later on in the course. Stroustrup's chapter 7.7 (References) also elaborates on the difference of pointers and references.
From a technical point of view, references are not that different from pointers. Chances are high they'll even compile to the same byte code. You can check that by looking at the disassembler output if you're feeling adventurous!
Type conversions
For the conversion of simple numeric types implicit type conversions do the right job most of the time. For example, given these variables:
double a{1.0};
int b{1};
int c{2};
Try this:
cout << "double / int = " << a / c << endl;
cout << "int / int = " << b / c << endl;
Can you explain your findings?
In situations where the implicit conversions are not enough, C++ has a variety of operators to explicitly convert between variable types. Both primitive and more complex types can be converted this way. Read chapter 11.5 (Explicit Type Conversion) in Stroustrup's C++ book as an introduction.
The four explicit type casting operators are: static_cast, dynamic_cast,
reinterpret_cast, const_cast.
Off topic: Did you notice the way the variables got initialized? Using braces to initialize got introduced in C++11 and you should use it too! You can read all about initialization on cppreference' webpage on initialization.
static_cast
Converts between the static types of variables. For primitive types, this is
equivalent to "normal" type conversion. In the case of conversion between types
of pointers to related classes, no runtime check is done. The implications of
this will be made clear later in the course. For now, you can use static_cast
for regular type conversions as in:
int a = 1;
int b = 2;
double c = static_cast<double>(a) / static_cast<double>(b);
(which will faithfully result in c being 0.5 instead of 0 when one would
omit the casts; check it!)
dynamic_cast
Performs a runtime-checked conversion (as opposed to the static_cast). The
reason for its existence will be made clear later on in the course as we
discuss polymorphism. You don't need to know more at this moment.
reinterpret_cast
Converts a pointer to "whatever" to a pointer to "whatever else" (no matter the size of the "whatever"!). No other (static nor dynamic) type checking is done whatsoever! Like so:
// Suppose we have a good old double
double foo = 1.234;
// Let's make a pointer to that double which pretends to point to an integer
int* bar = reinterpret_cast<int*>(&foo);
// Look at the garbage!
cout << (*bar) << endl;
Beware, technical stuff! The above code prints -927712936 on my
machine. Why? The hex representation of 1.234 in 64bit IEEE 754 double
precision is 0x3ff3be76c8b43958. Interpreting this piece of data as a
signed integer (which is 32bit two's complement on my machine) only takes the
4 least significant bytes into account, 0xc8b43958, which happens to be the
representation of -927712936. That's why!
With a reinterpret_cast, we're effectively looking at some part of the memory
and telling C++ to interpret the raw bits and bytes in some other way.
The uses of this type of cast are limited to rather a low-level system stuff and
fall in a category similar to void*. Use it only when you're 100% sure you
know what you're doing! (Unless you're just fooling around; it's fun!)
const_cast
Casts the const away. Having these around might be a sign of flawed design
since you can do all sorts of nasty things like:
void i_look_harmless(const int* a) {
// but I'm really evil!
(*const_cast<int*>(a))++;
}
Golden rule
Avoid C-style explicit type conversions (i.e., (T) var), especially on user-defined types. They have no notion of class hierarchies and are potentially dangerous!
Functions
One of the more fundamental features of practically every programming language
are functions. The moment you write your first C++ program, you've defined your
first function, int main(int argc, char* argv[]), which is the entry point of
every C / C++ program.
You've already declared & defined a function in the previous lab session. Let's now focus for a moment on how to pass data to a function and how to get data back.
Argument passing
By value
The semantics of passing arguments to a function is that of a variable
initialization. This is very important when you'll be passing around
objects to (member) functions. Given a function f declared as:
void f(double x);
When you call this function and pass it a variable as an argument, as in:
double a = 1.3;
f(a);
the function f has its own variable x which, at the moment of calling f
is initialized to have the same value as a from the calling context. It's
effectively equivalent to saying double x = a;. This variable x will cease
to exist once the execution path returns from the function. Whatever happens
to x inside the function f will have no effect whatsoever on the variable
a since it's just a local copy. This is called pass by value.
By reference
Another possibility is to pass by reference. Consider a function g
declared as:
void g(double& y);
You can call this function in the same way as before:
double b = 1.4;
g(b);
The HUGE difference though is that the semantics of initialization now
dictate that the local reference y is initialized to be just another name for
the variable b; equivalent to saying double& y = b;. By consequence, both
b and y "share" the same place in memory. Whatever changes are made to y
inside the function g, they will alter the value of b too.
By reference, using a pointer
Yet another way of passing the same argument is, again by reference, but using a pointer. The function is now declared as:
void h(double* z);
Calling h requires passing the address (cfr.: address-of operator &) to a
variable:
double c = 1.5;
h(&c);
Just as in the previous case, both *c and z refer to the same place in
memory because the semantics of passing the argument to h is equivalent to
double* z = &c;. Again, whatever happens to z inside the function h will
have an effect on c.
Note that although the variable c is passed by reference, its address,
&c is actually passed by value. The address IS the reference!
Why bother?
Why is passing arguments by reference useful in some cases? Either we want the called function to be able to modify the passed object. This way the arguments are being used as both the function's input and output. Or it's not convenient to pass by value because we don't want to make copies of objects (they are either too large, not copy-constructable, or some other reason). Another important reason to pass objects by reference is to make use of C++'s polymorphism, which works with pointers and references only.
If, in any of the above cases, you want to restrict the called function's
ability to alter the variable that's being passed by reference, you must use
const! Either you pass a reference to a constant variable:
void g(const double& y) {
y = 2.0; // ERROR! It's illegal to change y's value
}
or you pass a pointer to a constant variable:
void h(const double* z) {
(*z) = 2.0; // ERROR! It's illegal to modify the variable z is pointing to
}
Important Use const as much as you can to make sure values that should
never be
changed are effectively left unaltered! Using const is an important feature
that makes writing programs less error-prone. Read more about const-correctness on
the popular C++ FAQ.
Value return
Returning values from functions is very similar to passing arguments, just the other way around. Variables are also returned with the semantics of initialization. Given a function:
double gimme_one() {
double one = 1.0;
return one;
}
Called as:
double a = gimme_one();
The sequence of operations is as follows:
- Inside
gimme_one()a local variableoneis created and assigned the value1.0 - On return, the value of this variable is copied, which is equivalent to saying
double a = one; - When leaving
gimme_one(), the local variableoneis destructed. Its copy,alives on though
This is the most common way of returning stuff from functions. On some occasions, you'll come across returning pointers or references to values. Make sure you know what you're doing since you could be returning a pointer or a reference to a local variable that disappears after returning from a function. For example:
double* f() {
double whatever = 2.0;
return &whatever;
}
Will get you in trouble! It might work in some cases because of how memory is structured on the stack, but there's no guarantee whatsoever. You're basically poking around in a piece of memory that's not supposed to be there anymore.
Overloading
In C++ you can define functions that have equal names and different argument lists. If no ambiguities arise, the matching version will be chosen on compile time based on the number and types of the provided arguments.
The process of choosing the right function is called overload resolution. At first sight, it looks straightforward, at least for relatively simple cases, but it can get pretty tricky when not used carefully (mind the implicit type conversion for instance). If you want to know the details, read chapter 12.3 (Overloaded Functions) in Stroustrup's C++ book.
Note that the return type is not taken into account during overload resolution. For example, this works:
void foo(int bar) {}
bool foo(string bar) {}
But this is not permitted:
void foo(int bar) {}
bool foo(int bar) {}
Since ambiguities arise:
In function 'bool foo(int)':
error: new declaration 'bool foo(int)'
error: ambiguates old declaration 'void foo(int)'
Exercises
Swap
Write (and test!) a function that swaps the values of two integers. To get you
practicing your git abilities, create three different branches:
* One branch (swap_by_ptr) that swaps the values using pointers to the integers
* Another branch (swap_by_ref) that does the same using references
* A third branch (swap_ptr_by_ref) that swaps the values of the pointers themselves (by reference) and not the values of the variables pointed to.
Fix my code
Fix the code to do what it should do according to the comment. Changing the return type of doubleNumber is not allowed!
#include <iostream>
void doubleNumber(int num) {num = num * 2;}
int main() {
int num = 35;
doubleNumber(num);
std::cout << num; // Should print 70
return 0;
}
Multiplication, the hard way
Write a recursive function int mul(int x, int y) that returns the product x*y (you can assume that both x and y are positive). Don't use loops!
You may only use the + and - operators for doing math.
Start a new branch and rewrite the previous function. This time only + is allowed for doing math.
You might find the static keyword interestingly useful (read about it here).
Nevertheless, the usability of this program is limited as you'll notice.
Knapsack
Write a program that solves the knapsack problem recursively: given a list of items, each having a weight and a value, determine the maximum value you can carry along in a bag that can handle a specific weight.
Define the function:
int knapsack(int capacity, const ItemList& items);
This returns that maximum value given the weight one can carry. Use the following shorthand notations:
typedef std::pair<int, int> Item; // weight, value pairs
typedef std::list<Item> ItemList;
Monte Carlo Pi
Write a program that calculates an approximate value of pi using Monte-Carlo sampling (there's a section on Monte Carlo sampling in the above Wikipedia article).
I suggest you take a look at the #include <random> header and don't use the old C-style random number generation.
See: Pseudo-random number generation.